Level 1 - Enterprise-level architecture
This section builds on the Level 0 - Enterprise and Strategic Context to describe enterprise-wide and cross-domain data and data platform architecture concepts.
Why It Matters
Establishing a clear enterprise-wide, cross-domain design—the “town plan” for data—ensures that platform architecture, capabilities, and investments are purposefully coordinated across the organisation.
This reduces duplication, enables shared infrastructure, and is critical to building a scalable, interoperable, and sustainable data platform aligned with the organisation’s long-term vision.
Table of Contents
- Key concepts
- Reference topologies
- Hybrid federated mesh topology
- Enterprise Data Platform Reference Architecture
- Enterprise (Logical) Data Warehouse Reference Architecture
- Enterprise Information and Data Architecture
- Enterprise Metadata Architecture
- Enterprise Security
- Enterprise Data Governance
- Enterprise Billing
Key concepts
The following key concepts are used throughout this knowledgebase.
Domain-Centric Design
Using domains as logical governance boundaries helps ensure data ownership and accountability. This approach aligns with the data mesh principle of decentralizing data management and providing domain teams with autonomy.
Our use of this term draws inspiration from Domain-Driven Design and Data Mesh principles. See Domain driven design

Domain
Domains relate to functional and organisational boundaries, and represent closely related areas of responsibility and focus.
- Each domain encapsulates functional responsibilities, services, processes, information, expertise, costing and governance.
- Domains serve their own objectives while also offering products and services of value to other domains and the broader enterprise.
- Domain can exist at different levels of granularity and their boundaries may not be obvious. They are not necessarily a reflection of the organisational chart.
Subdomain
A subdomain is a lower-level domain within a parent domain that groups data and capability related to a specific business or function area.
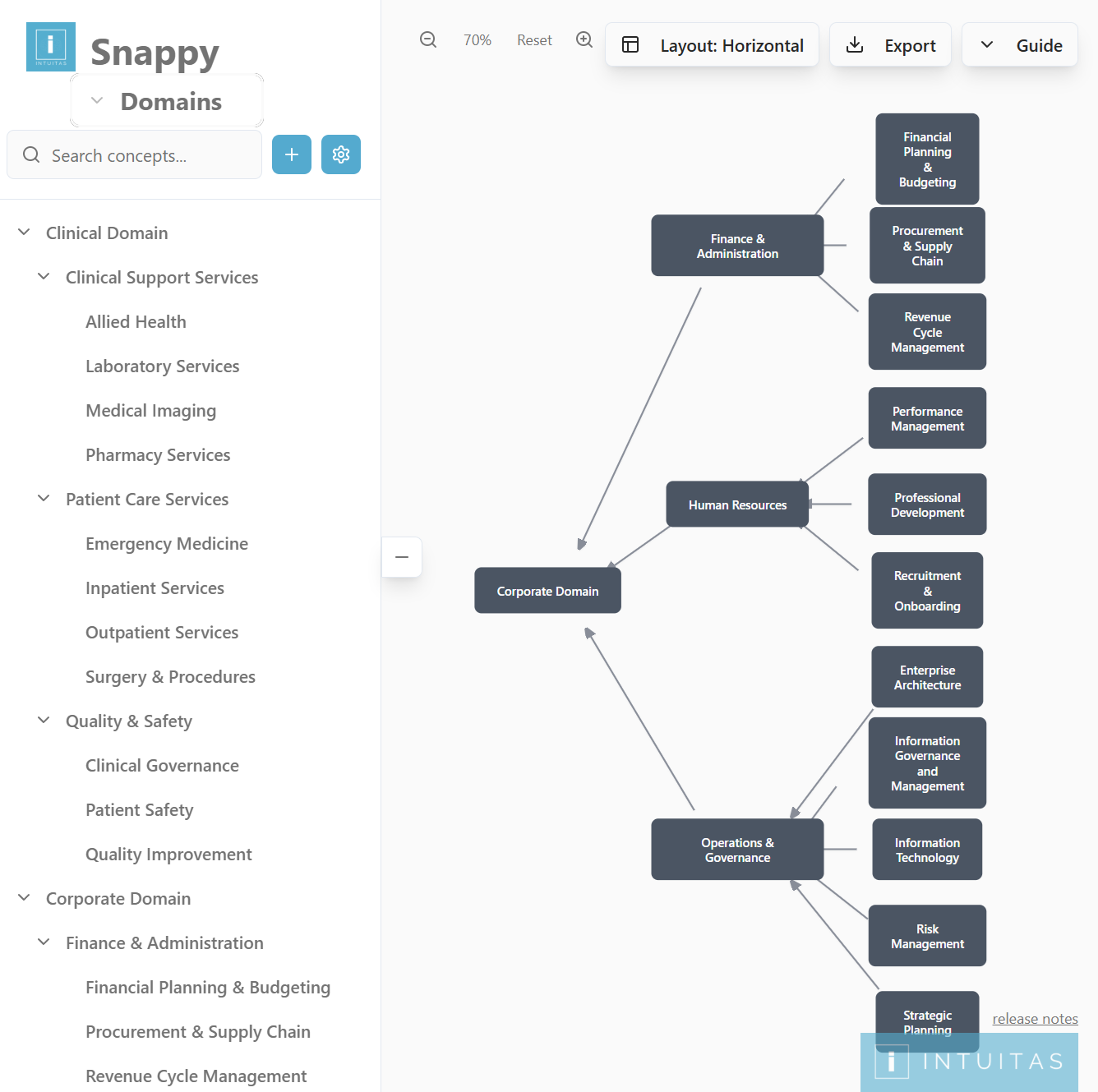
Data Mesh
A data mesh is a decentralized approach to data management that shifts ownership and accountability to domain teams, enabling them to treat their data as a product. Each domain is responsible for creating, maintaining, and sharing high-quality, discoverable, and interoperable data products with other domains.
The data mesh approach emphasizes domain autonomy, self-serve infrastructure, interoperability, and federated governance. It is not a one-size-fits-all model; its suitability depends on an organisation’s context, culture, and capabilities, and its adoption will vary in maturity and success across organisations.
Domain Topology
A Domain Topology is a representation of how domains are structured, positioned in the enterprise, and how they interact with each other. See Data Mesh: Topologies and domain granularity
Data Fabric
A data fabric is a unified platform that integrates data from various sources and provides a single source of truth. It enables data sharing and collaboration across domains and supports data mesh principles.
Data Mesh vs Fabric
A data mesh and fabric are not mutually exclusive. In fact, they can be complementary approaches. A data mesh can be built on top of a data fabric.
Reference topologies
Organisations need to consider the current and target topology that best reflects their strategy, capabilities, structure and operating/service model.
The arrangement of domains:
- reflects its operating model
- defines expectations on how data+products are shared, built, managed and governed
- impacts accessibility, costs, support and overall experience.
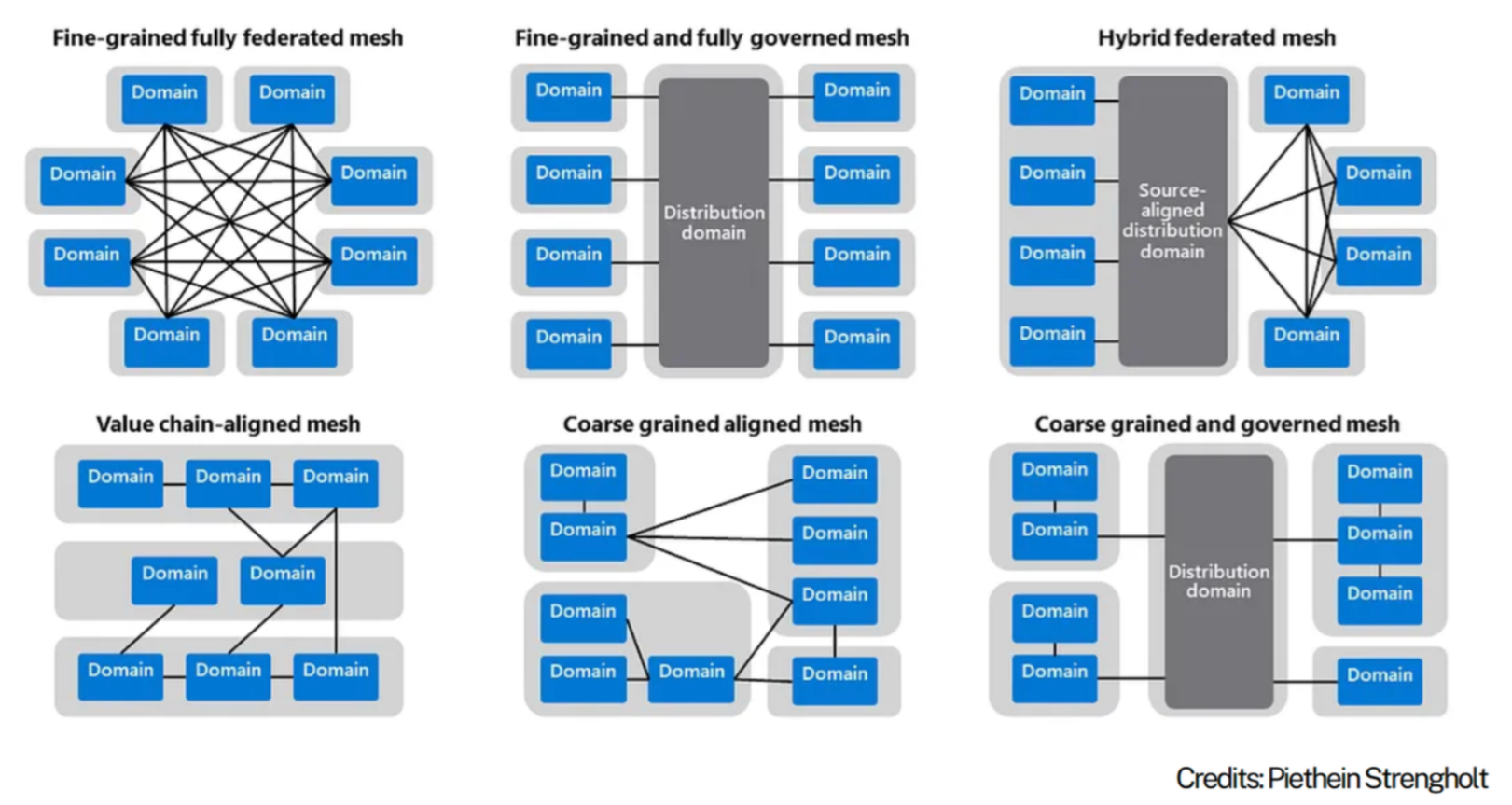
Source: Data Mesh: Topologies and domain granularity, Strengholt P., 2022
Hybrid federated mesh topology
This blueprint depicts a Hybrid Federated Mesh Topology, increasingly common in large enterprises and mature engineering practices. It integrates various distributed functional domains with a unified raw data engineering capability. While tailored for this topology, the guidance is broadly applicable to other configurations.
Key characteristics of this topology include:
Hybrid of Data Fabric and Data Mesh:
- Combines centralised governance with domain-specific autonomy.
- Offers a unified platform for seamless data integration, alongside domain-driven flexibility.
Fabric-Like Features:
- Scalable, unified platform: Connects diverse data sources across the organisation.
- Shared infrastructure and standards: Ensures consistency, interoperability, and trusted data.
- Streamlined access: Simplifies workflows and reduces friction for data usage and insights delivery.
Mesh-Like Features:
- Domain-driven autonomy: Empowers teams to create tailored solutions for their specific data and AI needs.
- Collaboration-focused: Teams act as both data producers and consumers, fostering reuse and efficiency.
- Federated governance: Ensures standards while allowing teams to manage their data locally.
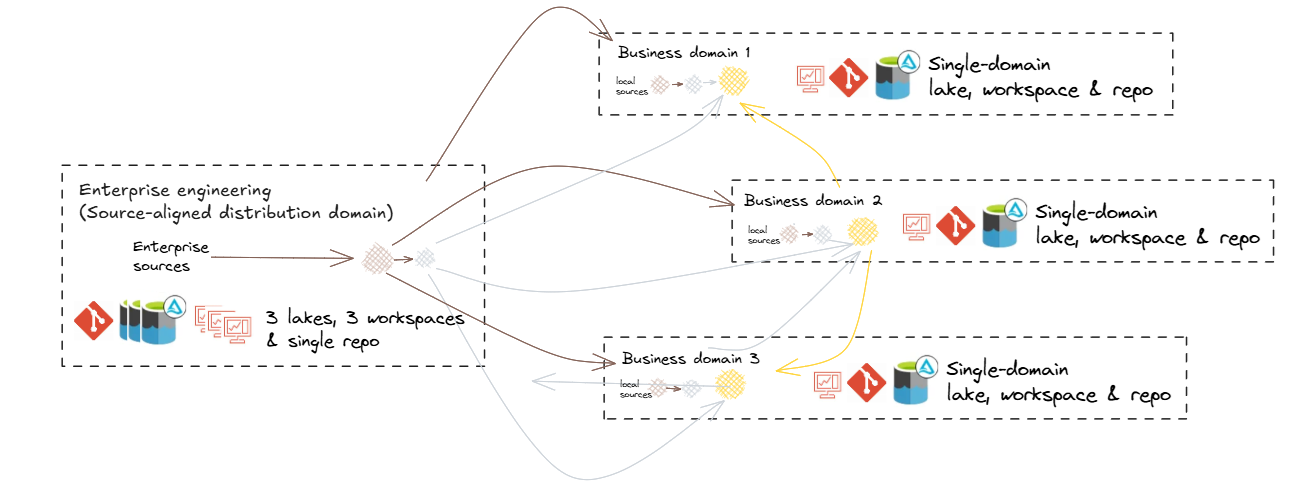
Hybrid federated mesh topology reflects a common scenario whereby centralisation occurs upstream for improved consolidation and standardisation around engineering, while federation occurs downstream for improved analytical flexibility and responsiveness.
Centralising engineering
Centralizing engineering tasks related to source data processing allows for specialized teams to efficiently manage data ingestion, quality checks, and initial transformations. This specialization ensures consistency and reliability across the organisation.
Distributed Local engineering
Maintaining a local Raw (Bronze) zone for non-enterprise-distributed data enables domains to handle their specific raw data requirements, supporting use cases that are not yet enterprise-wide.
Cross-Domain Access
Allowing domains to access 'gold' data from other domains and, where appropriate, 'silver' or 'bronze', facilitates reuse, cross-domain analytics and collaboration, ensuring data mesh interoperability.
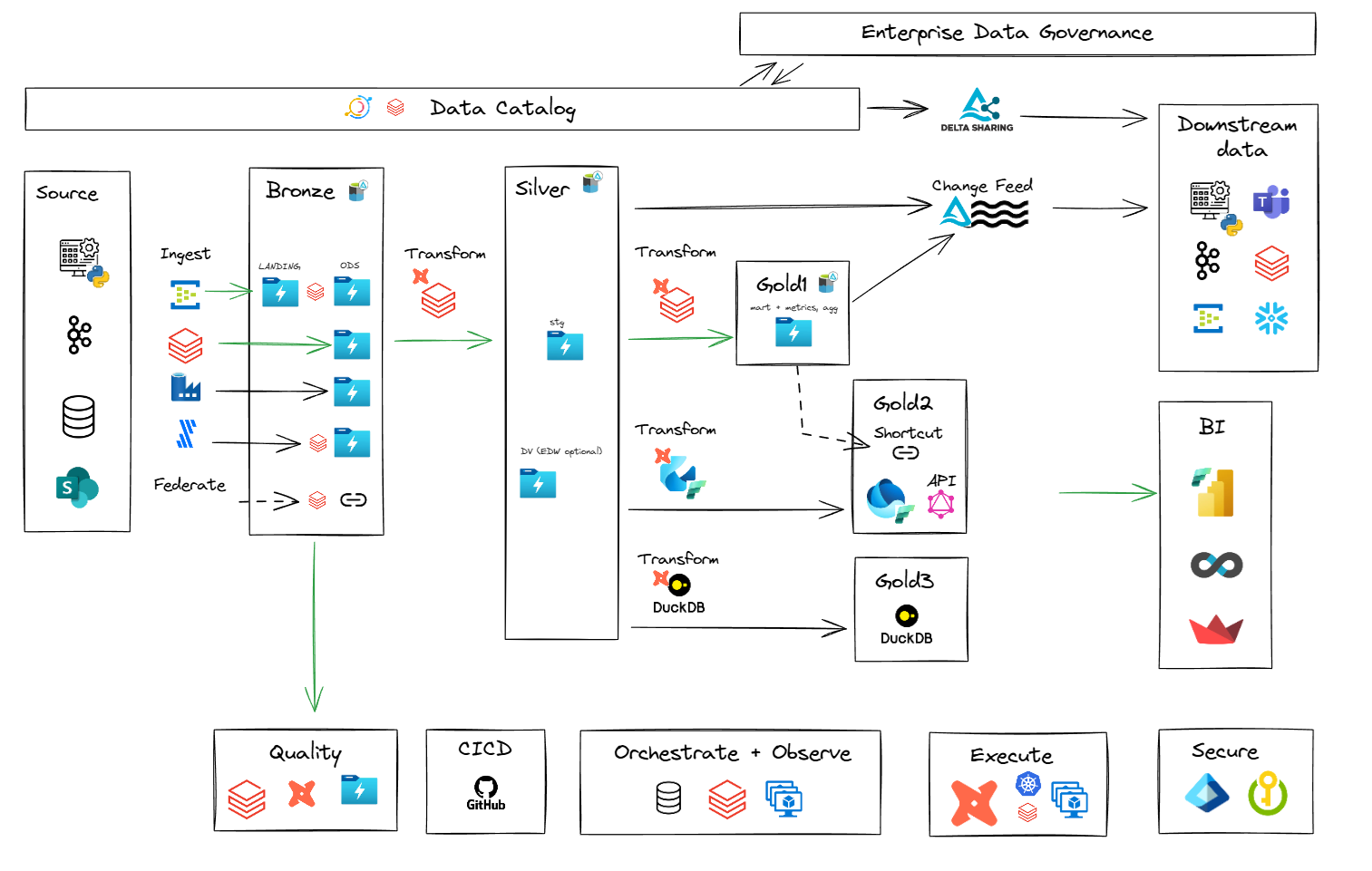
Enterprise Data Platform Reference Architecture
Describes the logical components (including infrastructure, applications and common services) that make up a default data and analytics solution, offered and supported by the enterprise. This artefact can then be used as the basis of developing domain-specific overlays.
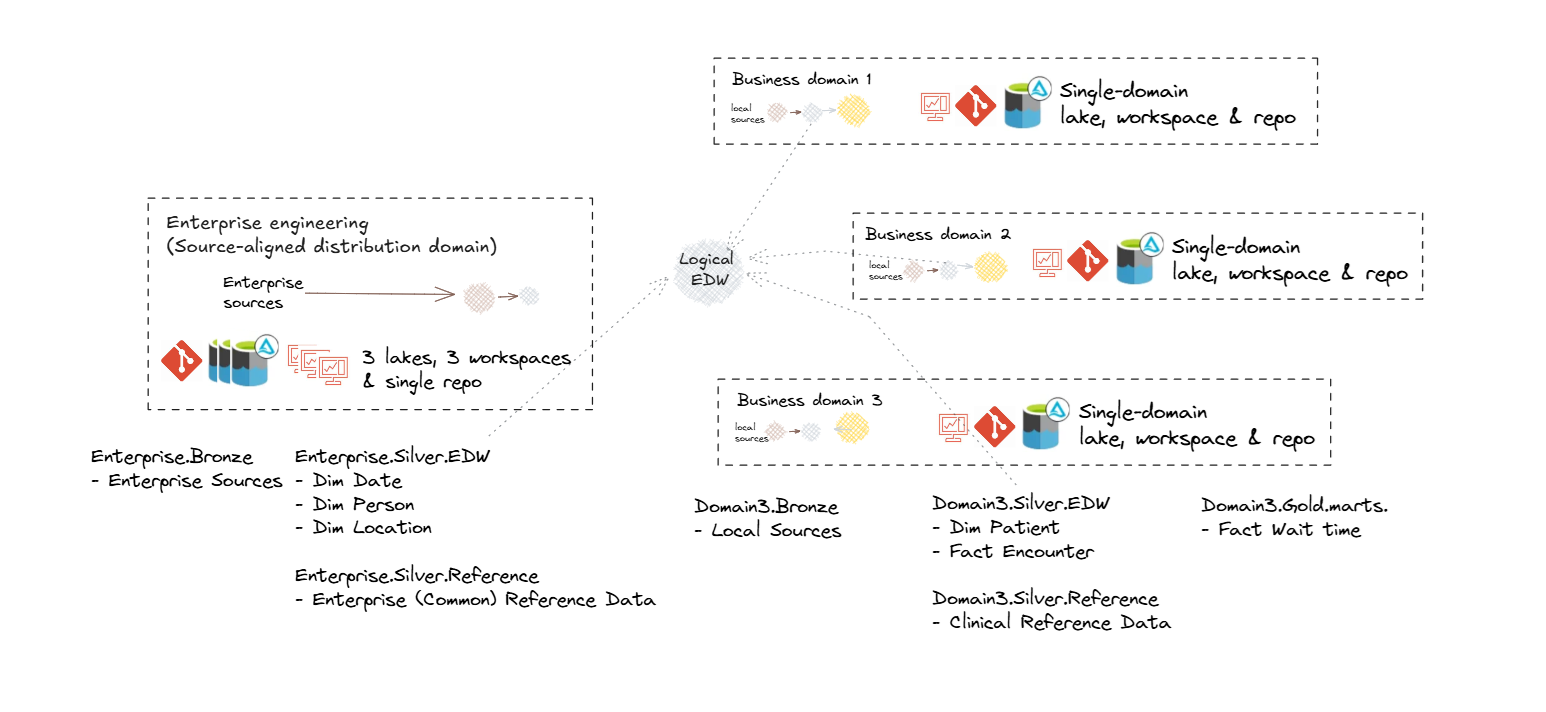
Enterprise (Logical) Data Warehouse Reference Architecture
An enterprise logical data warehouse retains the core properties of a traditional data warehouse—integrated, consistent, and analytics-ready data—while operating in a distributed, domain-oriented model.
Logical Data Warehouse topology is characterised by:
- Federated governance – shared policies and standards, but distributed custodianship, applied across the domain topology.
- Unified access – a common entry point for querying and consuming data regardless of its physical location
- Enterprise metadata – consistent definitions, lineage, and discovery across all domains via shared catalog.
This approach combines the scalability and agility of decentralised ownership with the trust and coherence of an enterprise-wide data platform.
Two-tier Mart Model
In this approach, we establish a two-tier mart structure: the EDW (Enterprise Data Warehouse) marts and the Infomart (IM) marts.
- EDW marts provide standardised, reusable datasets for enterprise-wide consistency.
- Infomart marts deliver domain and business-requirement specific assets.
Using both are available for enterprise-aligned, and domain oriented reporting and analytics.
Enterprise Information and Data Architecture
Solutions such as data warehouses and marts should reflect the business semantics relating to the scope of requirements, and will also need to consider:
- Existing enterprise information, conceptual and logical models
- Legacy warehouse models
- Domain information models and glossaries
- Domain business objects and process models
- Common entities and synonyms (which may form the basis of conformed dimensions)
- Data standards
Other secondary considerations:
- Source system data models
- Industry models
- Integration models
Enterprise Metadata Architecture
Metadata is an umbrella term encompassing various types of data that play critical roles across multiple domains, supporting the description, governance, and operational use of data and technology assets. It can be actively curated or generated as a byproduct of processes and systems.
Metadata Architecture Principles
The following principles reflect our design philosophy to ensure sustainable and effective metadata capability
| Principle | Description |
|---|---|
| Accessible | Metadata must be easy to find, search, and use and maintain by business, technical and governance stakeholders. |
| Dynamic | Automate collection and updates to keep metadata fresh and reduce manual work. |
| Contextual | Bridge the gaps between business, technical, governance and architecture perspectives and serve the right metadata, in the right place, in the right format for the audience. |
| Integrated | Metadata exists in an ecosystem across tools to support diverse workflows. |
| Consistency | Use common standards, terms, and structures; Ensure all metadata is current and in-sync. |
| Secure | Protect metadata as it may contain sensitive details. |
| Accountability | Clearly define roles for ownership and stewardship. |
| Agnostic | Avoid vendor lock-in where possible. Keep metadata portable and open to ensure flexibility and interoperability. |
Semantic and Data lineage
Semantic lineage and data lineage are critical concepts in a modern data intelligence capability to ensure clarity, trust, and traceability of data — from its business meaning to its technical origins and transformations:
-
Semantic Lineage maps business terms, definitions, and relationships across the data ecosystem, showing how concepts are represented and transformed across systems and domains.
-
Data Lineage tracks the technical flow of data from source to destination, including all transformations, to provide visibility, support data quality, and meet compliance and governance needs.
Together, they give a complete view of business and technical data flows, enabling stronger governance and management of data assets. Because they are often difficult to align and keep in sync, a unified approach, as provided in the reference architecture, is critical.
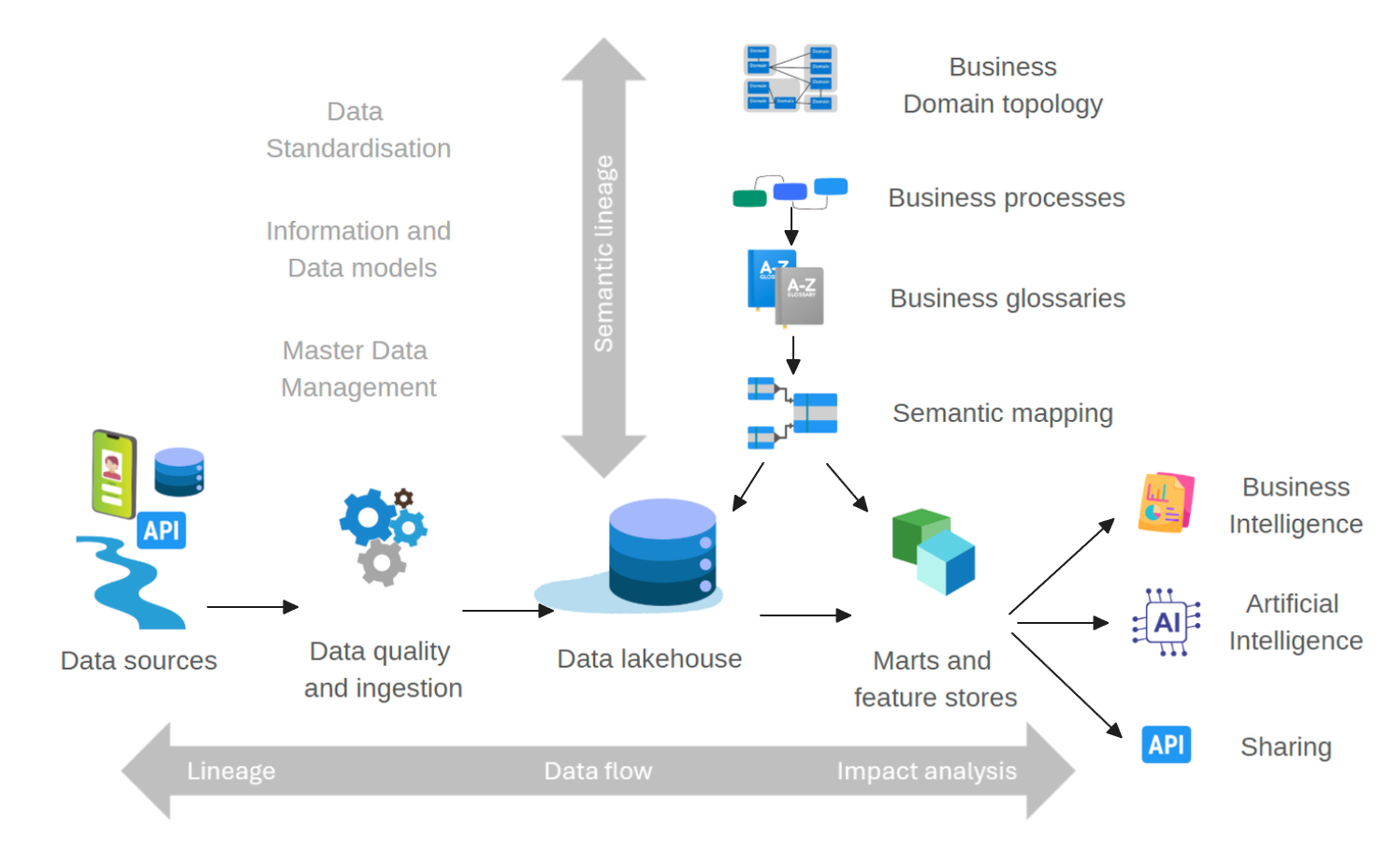
Metadata Objects and Elements
Metadata exists in various types, formats, and purposes, each essential for enabling:
- Data and Information Governance & Architecture – including semantic and data lineage, as well as privacy, access, and security - controls
- Data Engineering and Analytics Development
- Business Interpretation and Understanding – supporting the context and meaning of information and analytics
- Data Quality and Integrity
- Technical and Platform Administration
- Integration, Data Sharing, and Interoperability
The diagram below shows metadata objects and elements created and managed across various tools and contexts, each serving different purposes.
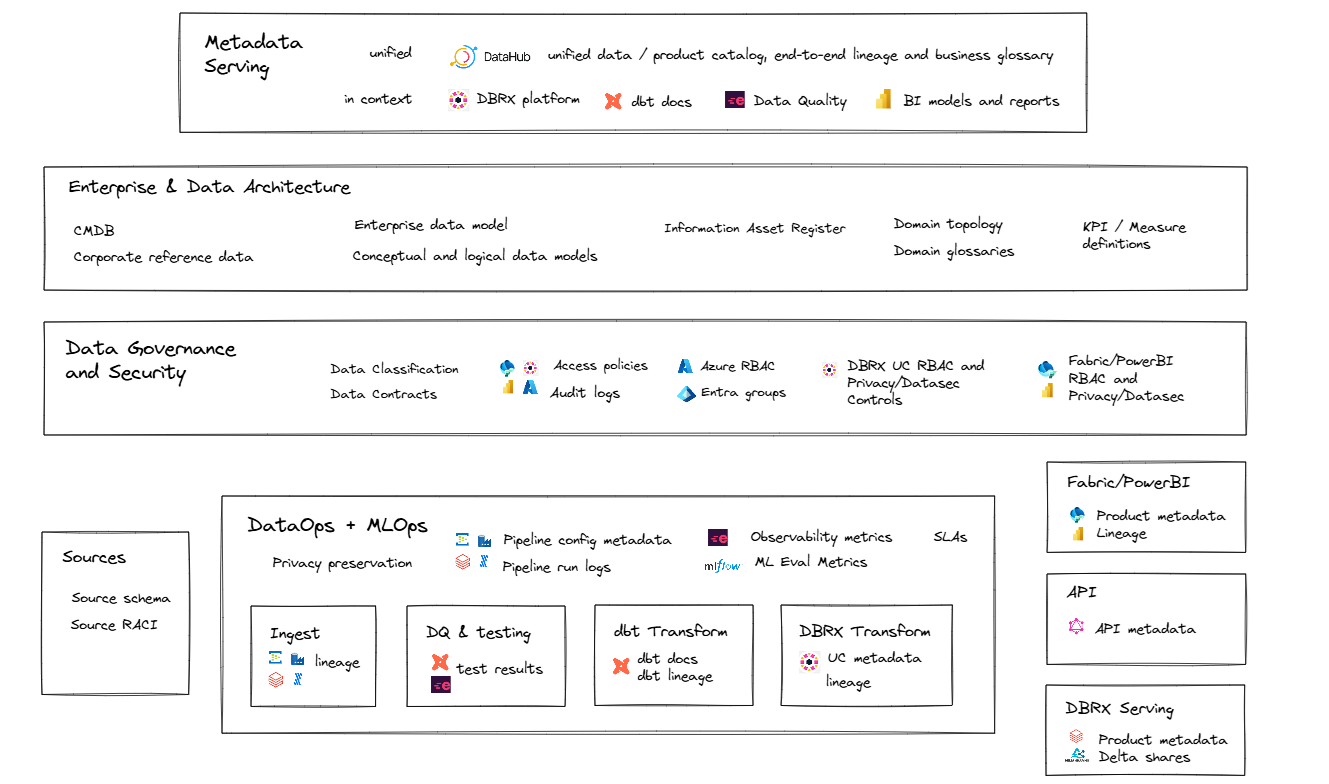
Metadata Consolidation and Synchronisation
Metadata consolidation and synchronisation are critical for achieving a consistent, unified view of data assets, enabling reliable lineage, governance, and context across the data ecosystem. This approach:
- Eliminates Silos: Aggregates metadata from diverse tools (e.g. dbt, Unity Catalog, PowerBI, MLflow) into a central catalogue like DataHub, ensuring all stakeholders access the same contextual information.
- Improves Trust and Traceability: Enables end-to-end lineage and visibility, helping users understand where data comes from, how it is transformed, and how it is used across platforms.
- Enables Automation and Governance: Supports data quality, access control, and policy enforcement through unified metadata APIs and standardized governance models.
The diagram below illustrates metadata objects and elements that are created and managed across diverse tools and contexts—each serving a distinct role in the broader data and technology ecosystem.
Data Architecture and Governance Metadata
Metadata is essential for effective data governance, providing necessary context and information about data assets, with the following metadata and tools being core to this capability.
Semantic modelling, mastering and lineage
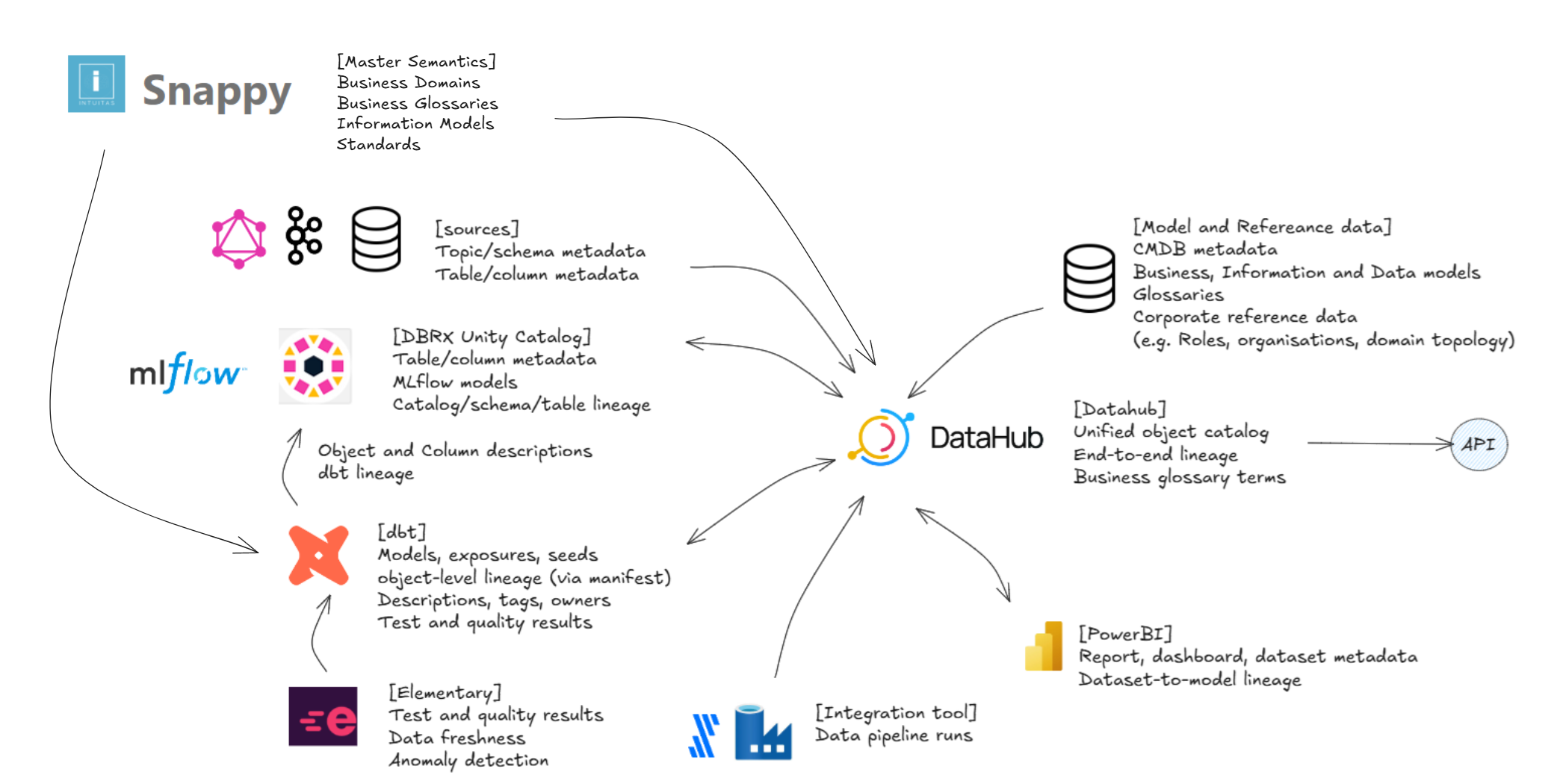
Snappy serves as a 'business-first' enterprise domain, model, standards and glossary authoring and mastering tool, and acts as the key driver of semantic lineage linking between true on-the-ground semantics, reference models and physical as-built metadata in Datahub.
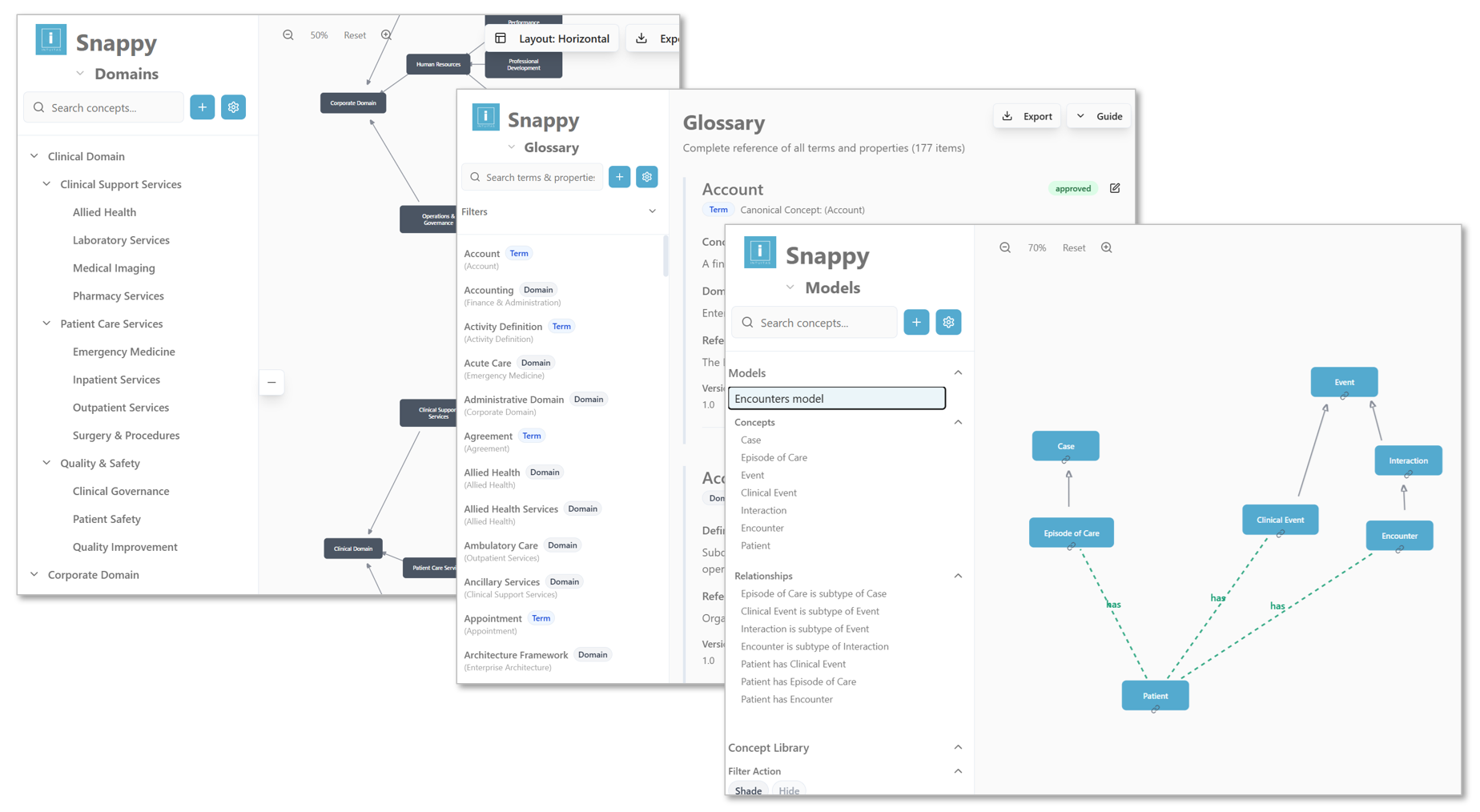
Unified metadata repository
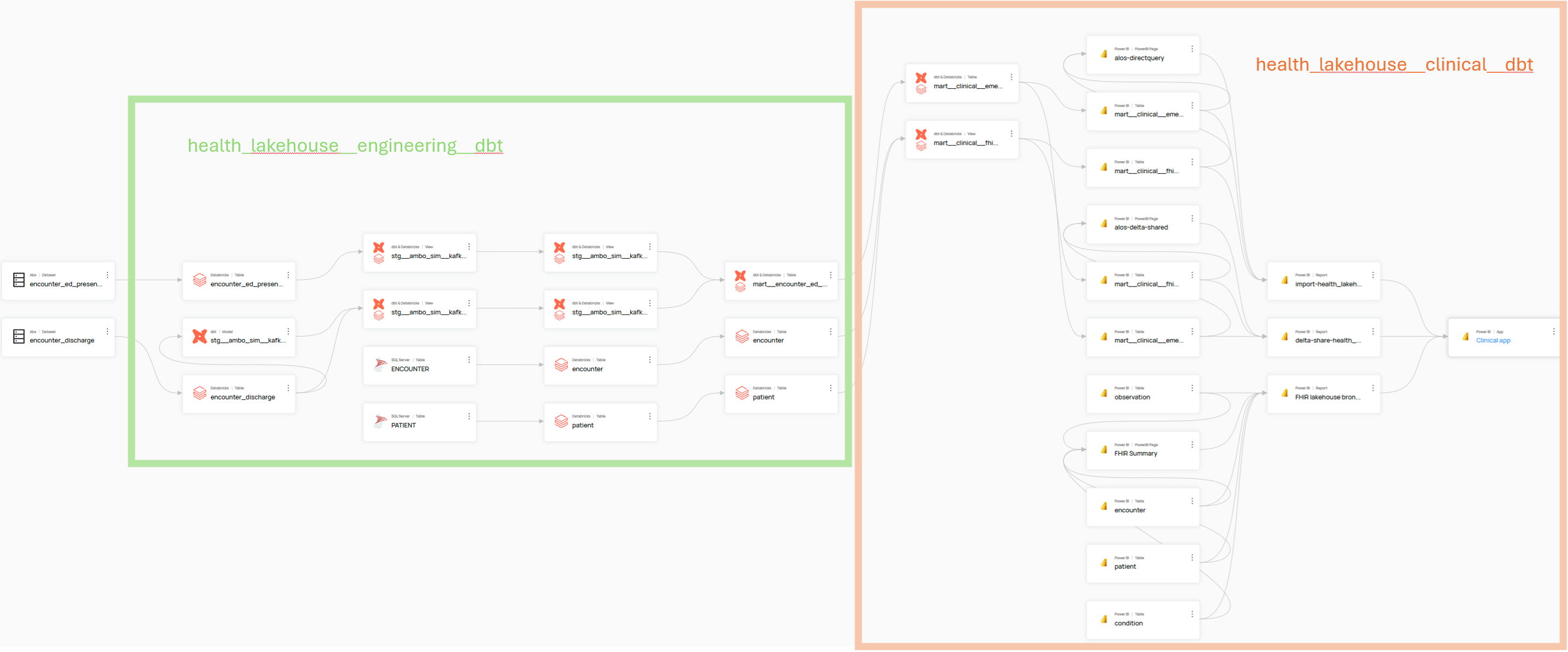
DataHub serves as a consolidation layer that connects and integrates end-to-end data lineage, business domain models, and their associated glossaries and data assets.
The diagram below illustrates how DataHub consolidates lineage across diverse platforms, domains, and projects providing a comprehensive view of data flows and relationships throughout the ecosystem.
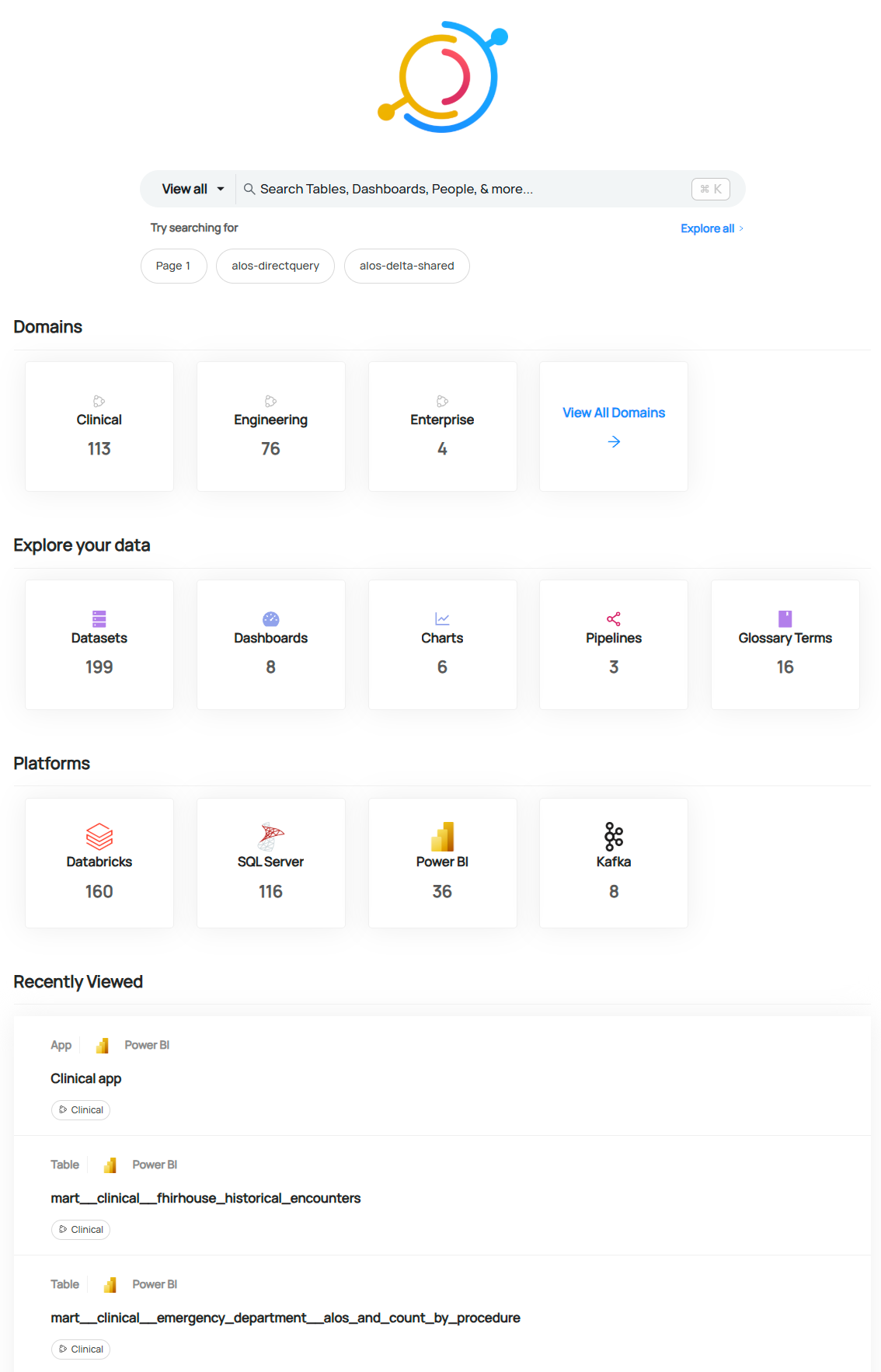
Example: Enterprise-wide summary of assets
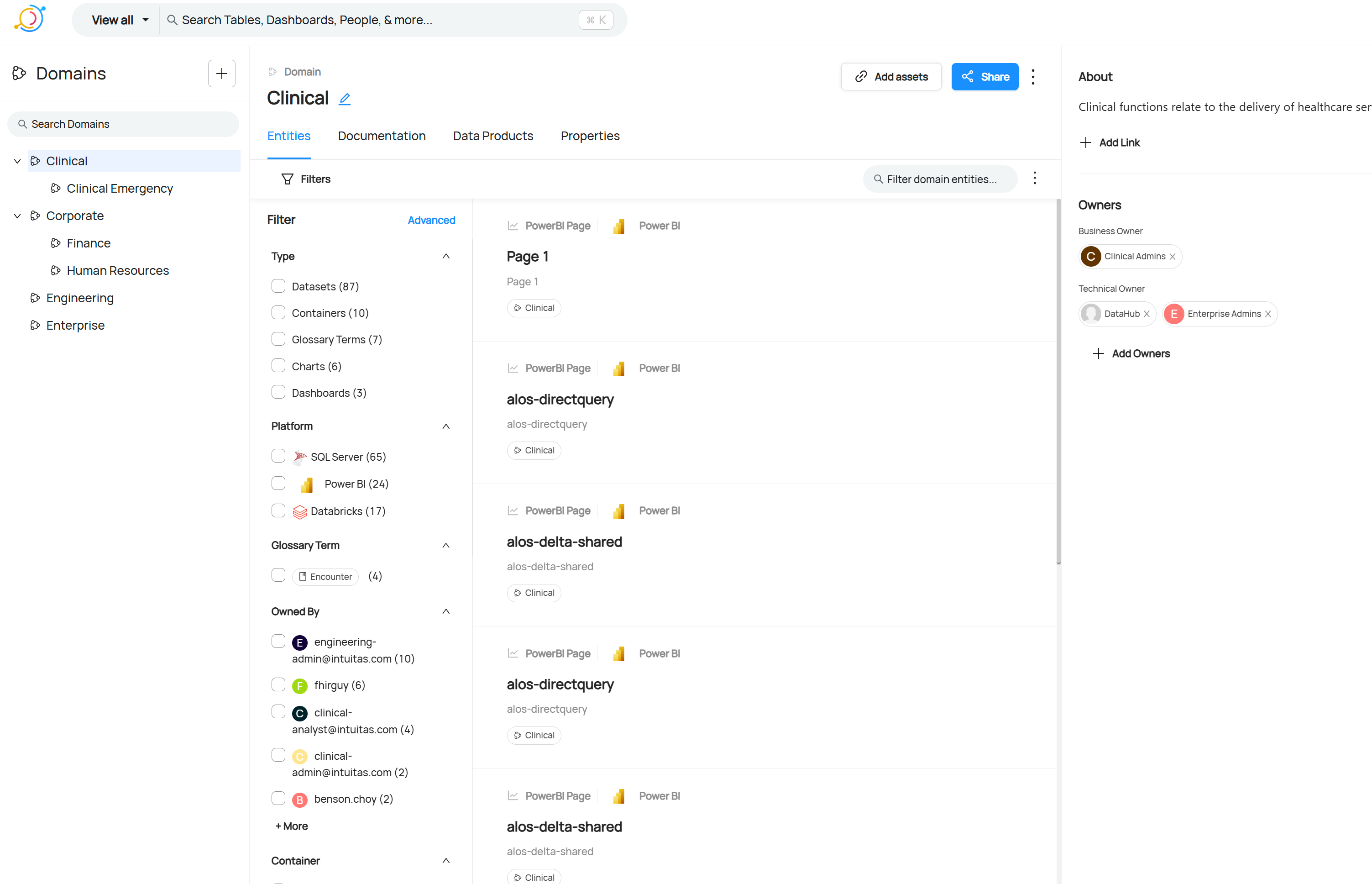
Example: Browse by business domain and filters
Example: Metadata search by term
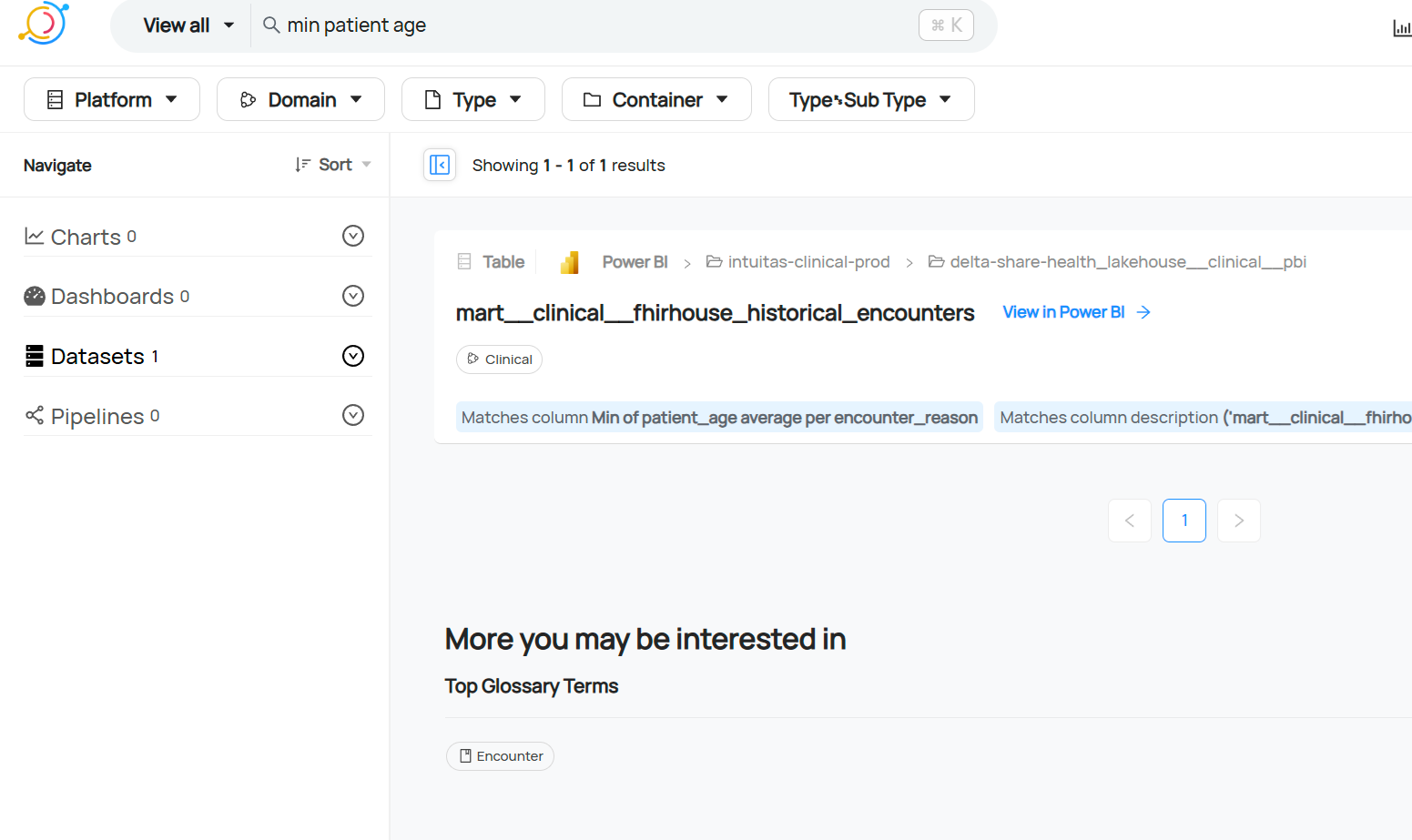
Example: User-driven mapping of glossary terms to measures
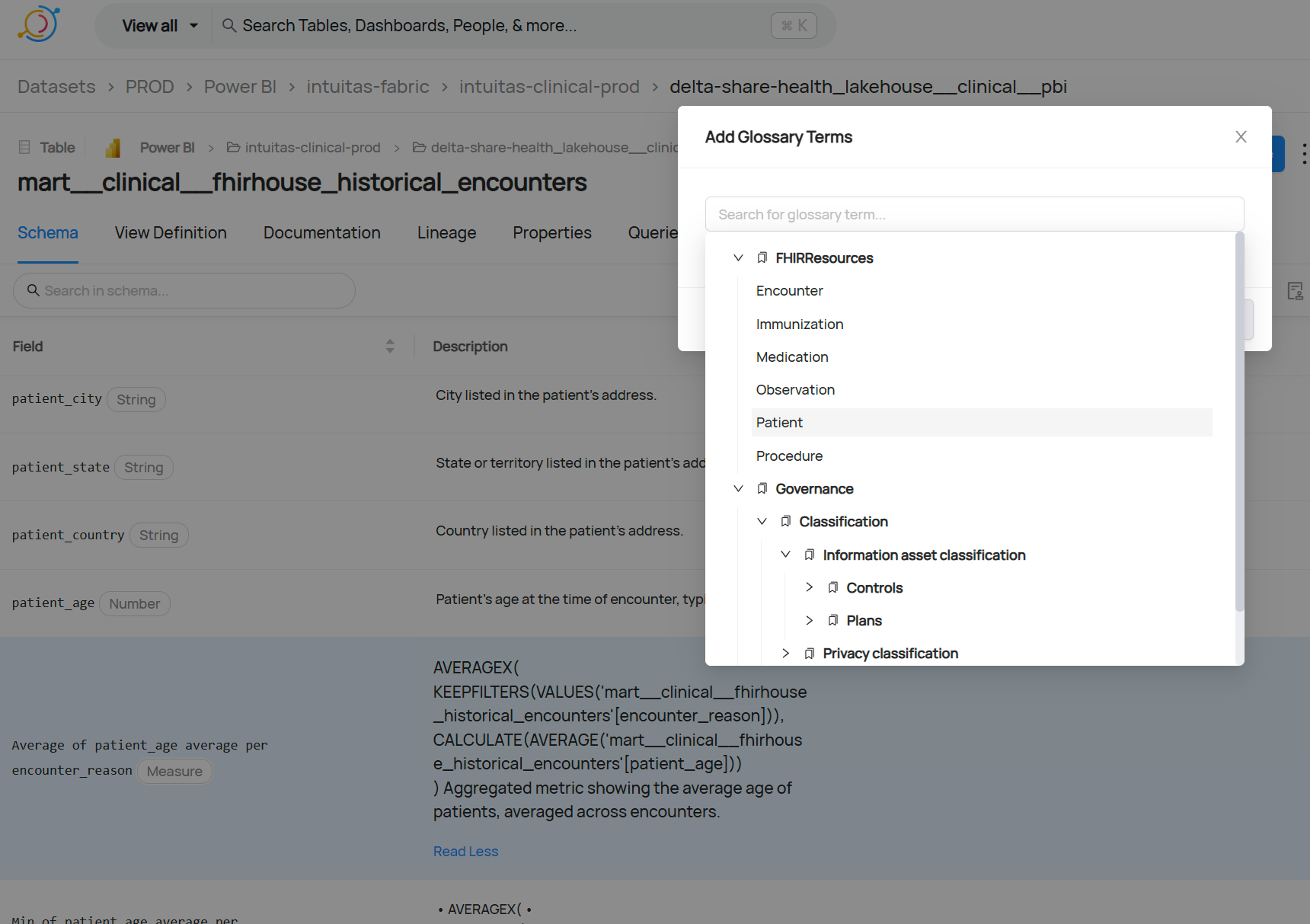
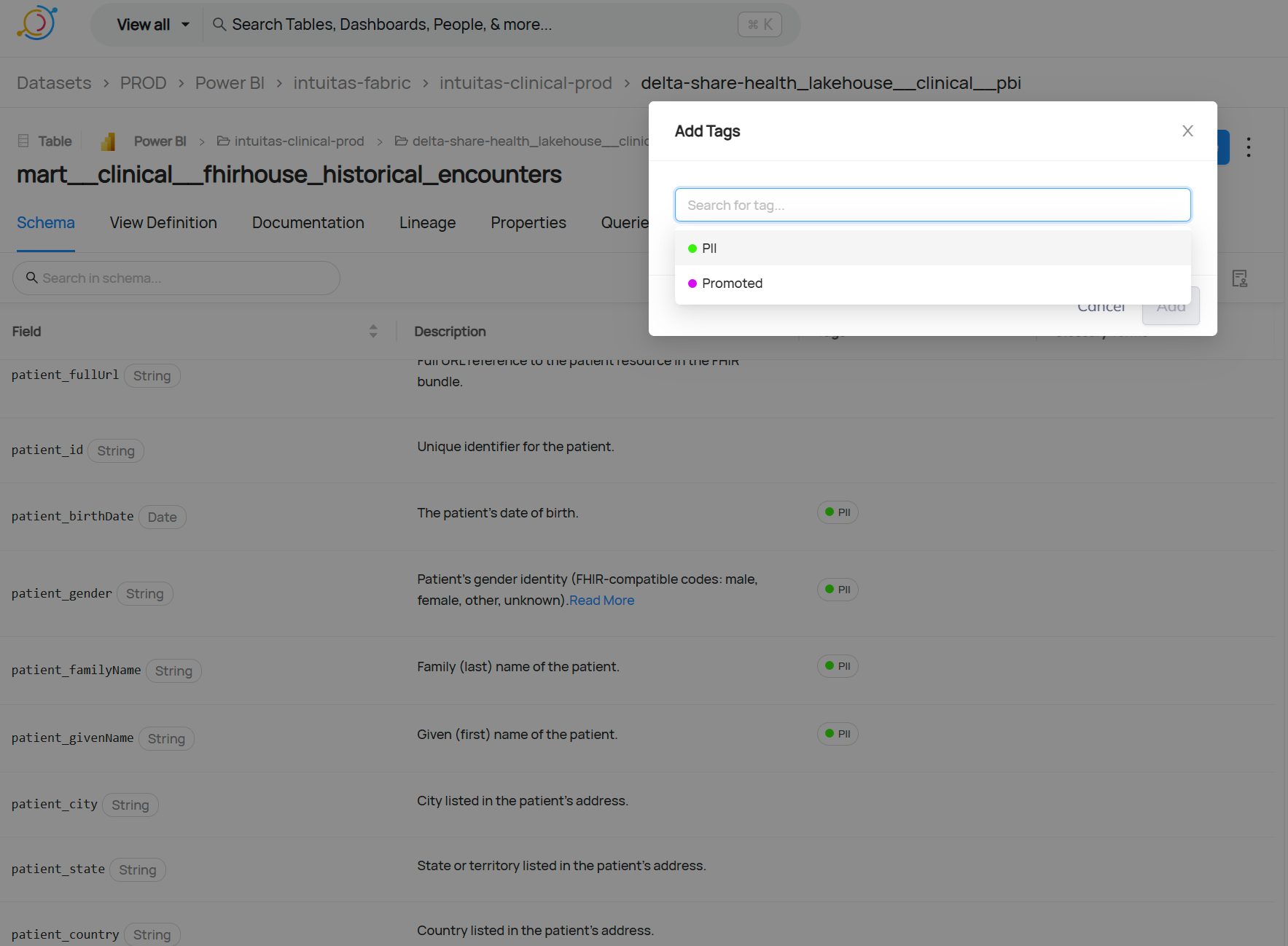
Example: User-driven tagging of PII
Analytics engineering metadata
- dbt Docs is the authoritative source for metadata related to SQL analytics engineering.
- It captures object, column, and lineage metadata, and provides a rich interface for discovery and documentation.
- dbt schema metadata is integrated with Databricks Unity Catalog.
- For more information, refer to standards and conventions.
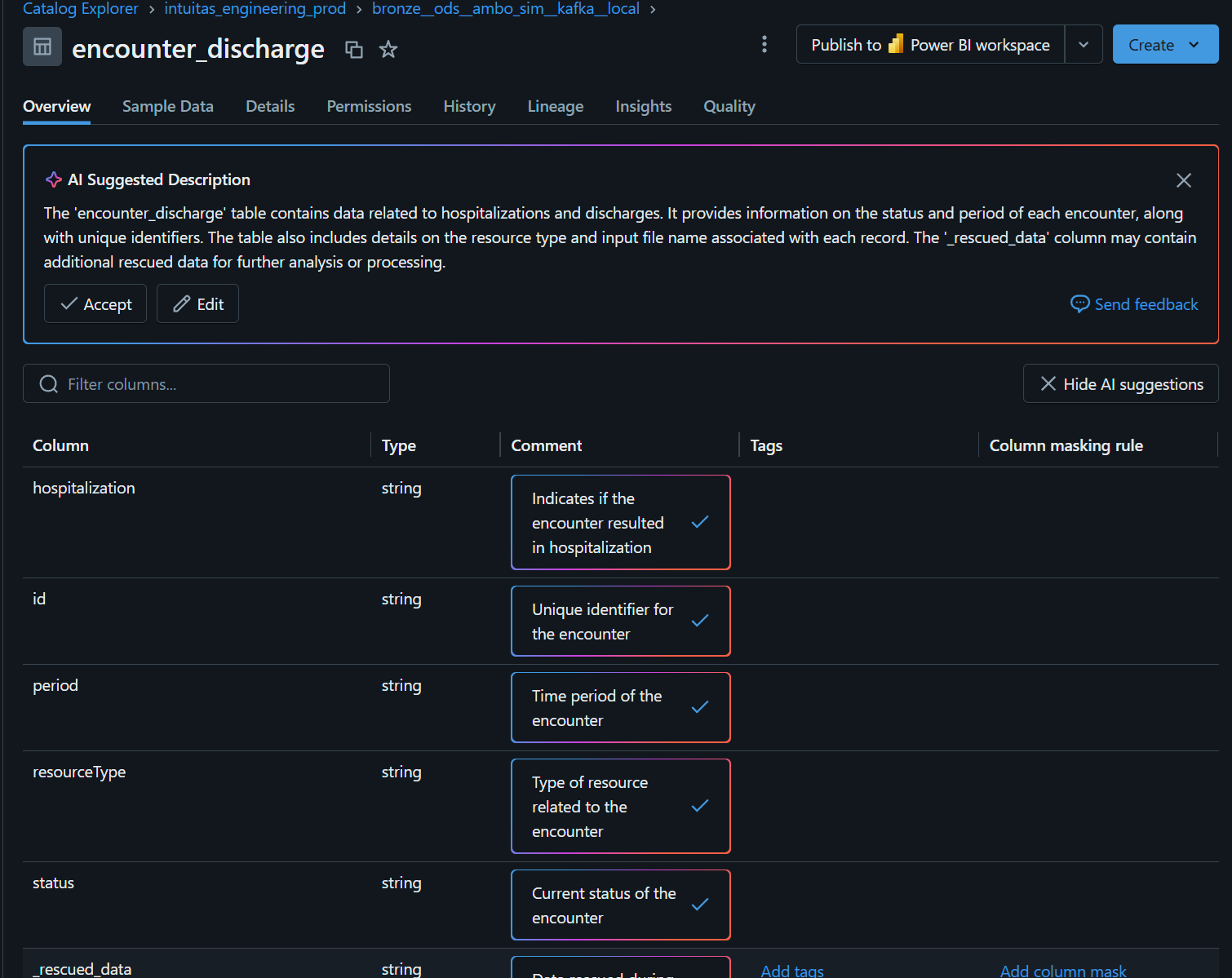
Databricks Unity Catalog Metastore
- Unity Catalog supports centralized governance of data and metadata across Databricks workspaces.
- Each region can have only one Unity Catalog metastore.
- The metastore uses designated storage accounts to hold metadata and related data.
- Unity catalog is able to
- store table, column and lineage metadata
- inherit schema metadata from dbt
- detect definitions using AI where they are missing
Recommendations and Notes:
- Assign managed storage at the catalog level to enforce logical data isolation.
- Metastore-level and schema-level storage options also exist.
- Review catalog layout strategies to align with domain-oriented design.
- The metastore admin role is optional but, if used, should always be assigned to a group, not an individual.
- The enterprise's domain topology directly influences the Unity Catalog design and layout.
Enterprise Security
Recommended artefacts:
- Description of security policies and standards for both the organisation and industry
- Description of processes, tools, controls, protocols to adhere to during design, deployment and operation.
- Description of responsibilities and accountabilities.
- Risk and issues register
- Description of security management and monitoring tools incl. system audit logs
Enterprise Data Governance
Recommended artefacts:
- Description of governance frameworks, policies and standards including but not limited to:
- Custodianship, management/stewardship roles, RACI and mapping to permissions and metadata
- Privacy controls required, standards and services available
- Quality management expectations, standards and services available
- Audit requirements (e.g. data sharing, access)
- Description of governance bodies and decision rights
- Description of enterprise-level solutions and services for data governance
- References to Enterprise Metadata management
Audit
Some organisations are bound to regulatory and policy requirements which mandate auditability.
Examples of auditable areas include:
- data sharing and access;
- platform access;
- change history to data.
Recommended artefacts:
- Description of mandatory audit requirements to inform enterprise-level and domain-level audit solutions.
Example questions and associated queries
As an Enterprise Metastore Admin:
1. Where are there misconfigured catalogs / schemas / objects?
2. Who is sharing what to who and is that permitted (as per access approvals?)
3. Who is accessing data and are they permitted (as per access approvals?)
Enterprise Billing
Large organisations typically need to track and allocate costs to organisational units, cost centres, projects, teams and individuals.
Here is where the Business Architecture of the organisation, domain topology, infrastructure topology (such as workspace delegations) and features of the chosen platform must to align.
See: - Funding and costing structures - Observability Solutions
Recommendations here align with the following Domain topology:
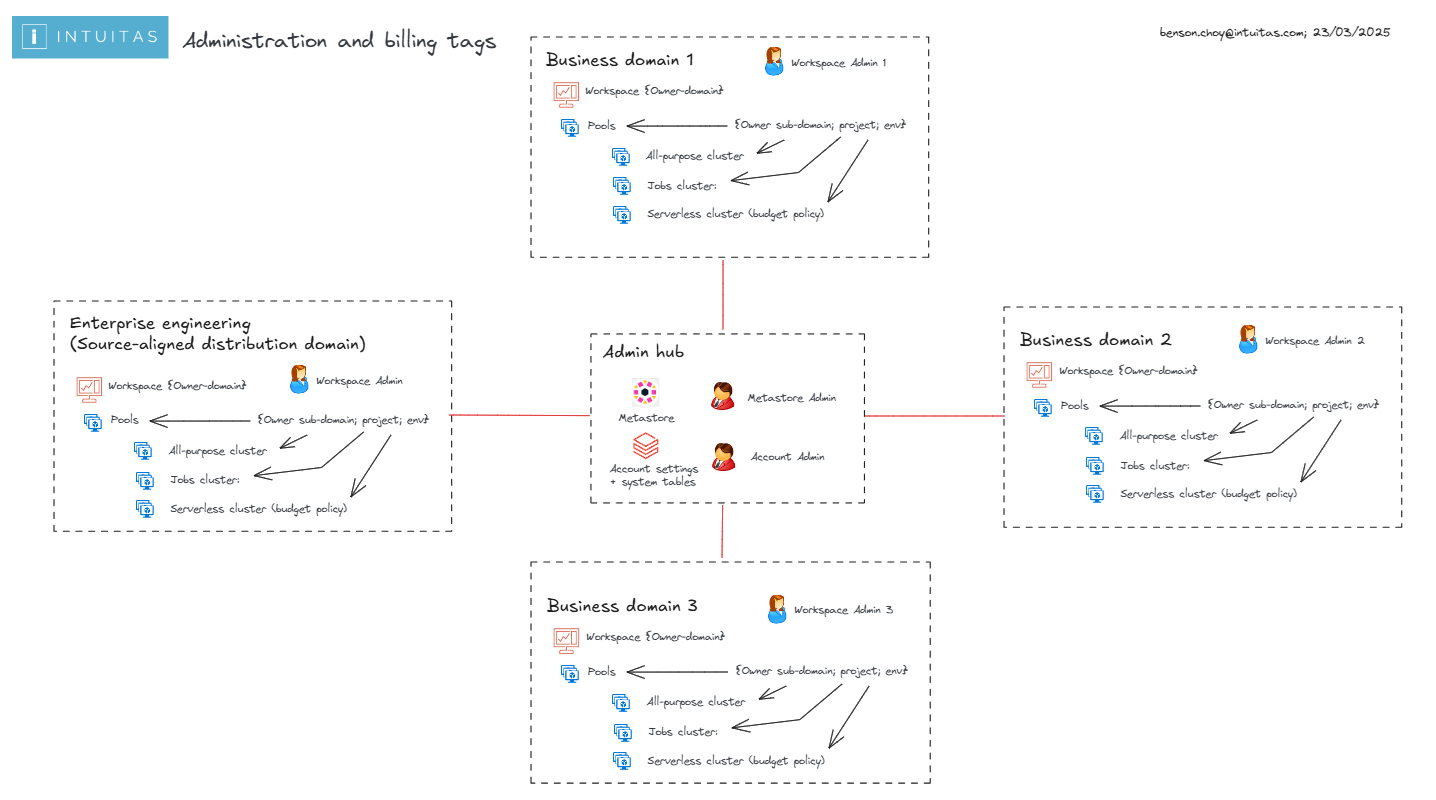
Databricks features for usage tracking
Metadata and tags
- In Databricks, metadata can be used to track activity:
- Workspace level
- Workpace owners identity
- Workspace tags
- Cluster level
- Authorised cluster users identities
- Cluster tags
- Budget Policies (Enforced tagging for serverless clusters)
- Job level
- Jobs and associated job metadata (*Note job-specific tags only appear when using Job Clusters)
- Query level
- Query comments (Query tagging is not yet a feature)
- Workspace level
- Tags from higher level resources flow through to lower level resources as per Databricks Usage Detail Tags
Cluster policies
- Cluster policies can be used to enforce tagging at the cluster level.
- Cluster policies can be set in the UI or via Databricks Asset Bundles in resource yaml definitions.
System tables
- System tables provide granular visibility of all activity within Databricks.
- System tables only provide DBU based billing insights, access to Azure Costs may require alternate reporting to be developed by the Azure administrator.
- By default, only Databricks Account administrators have access to system tables such as billing. This is a highly privileged role and is not fit for sharing broadly. Learn more
- Workspace administrators need to be delegated access to system tables, and likely restricted to their domain / workspace via dynamic system catalog views with RLS applied based on workspace ID. (See Dynamic Billing Solution below. Available on request) - see repo Databricks System Tools
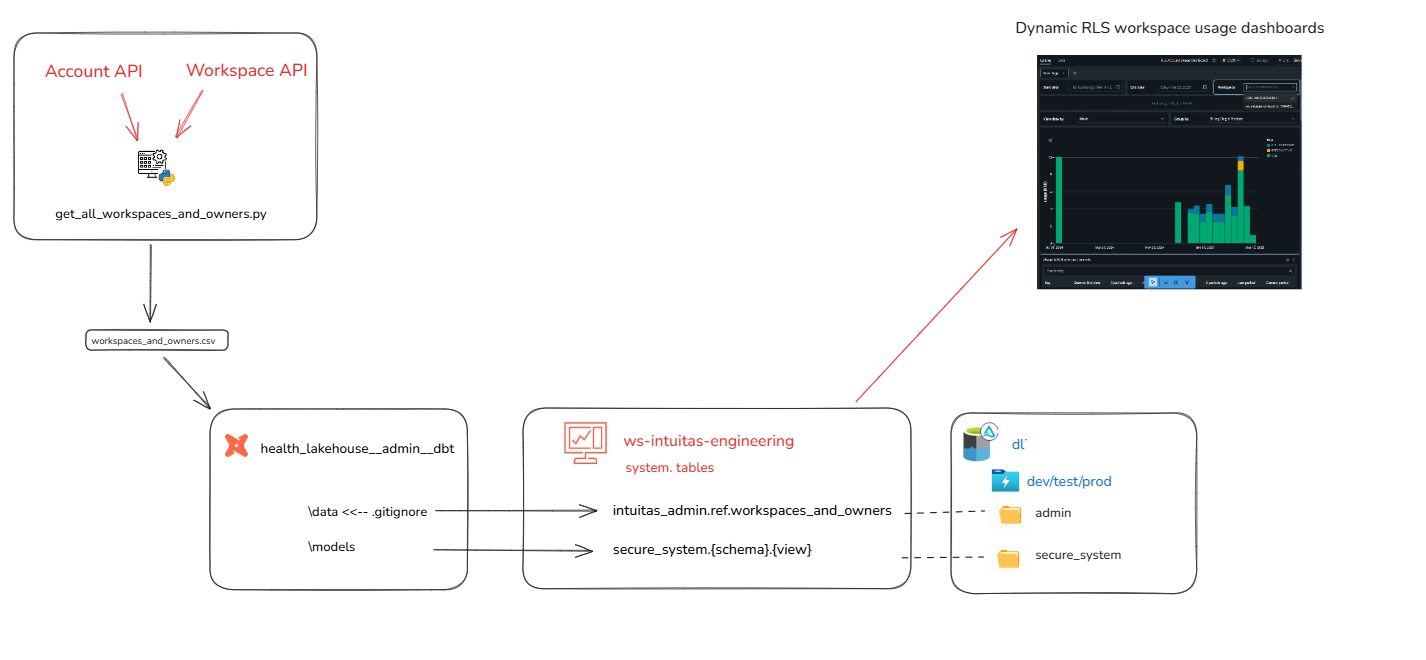
Usage reports
- Databricks supplies an out of the box Databricks Usage Dashboard which requires Account-level rights to view (To use the imported dashboard, a user must have the SELECT permissions on the system.billing.usage and system.billing.list_prices tables. Learn more
- Once workspace administrators have been delegated access to system tables, they can import a refactored version of the Databricks Usage Dashboard which are repointed to the RLS views. (See Dynamic Billing Solution above. Available on request)
Additional useful references: - Top 10 Queries to use with System Tables - Unlocking Cost Optimization Insights with Databricks System Tables
Domain / Workspace Administrator Role
- Workspaces are a container for clusters, and hence are a natural fit for representing a Domain scope.
- Domain administrators (i.e Workspace Admins) shall be delegated functionality necessary to monitor and manage costs withing their domain (Workspace):
- Ability to audit and shutdown workloads
- Ability to create budget policies and enforce them on serverless clusters
- Ability to create cluster tagging policies and enforce them on clusters
- Ability to delegate/assign appropriate clusters and associated policies to domain users
- Ability to call on Databrick Account Admin to establish and update Budget Alerts
Tagging convention
- All workloads (Jobs, serverless, shared compute) need to be attributable to at a minimum:
- Domain
- Environment: dev, test, uat, prod
- In addition all workloads may need more granular tagging in line with cost-centre granularity hence may include one of more of the following depending on your organisation's terminology:
- Sub-domain
- Team
- Business unit
- Cost centre
- Project
- In addition all scheduled Jobs would benefit from further job tags:
- Job name/id
- Job name/id
Typical observability requirements by role
As an Enterprise Admin
1. What workloads are not being tagged/tracked?
2. What is my organisation spending as a whole?
- In databricks DBUs
- Inclusive of cloud
3. What are my subteams/Domains spending on within the workspaces I have delegated?
- In databricks DBUs
- Inclusive of cloud
4. Where are we wasting money as an enterprise?
- Reinventing the wheel
- Over utilisation
As a Domain (workspace) Admin
1. What workloads are not being tagged/tracked?
2. What is my domain spending as a whole?
- In databricks DBUs
- Inclusive of cloud
3. What are my subteams spending on within the workspace I administer?
- In databricks DBUs
- Inclusive of cloud
4. What are the most expensive activities?
- By user
- By job
5. Where are we wasting money as an enterprise?
- Reinventing the wheel
- Over utilising
- Redundant tasks
- Inefficient queries